Introduction
Bluesky est une alternative décentralisée à Twitter. C’est une plateforme qui se veut plus ouverte, et qui place les utilisateurs au centre de l’écosystème. Une des fonctionnalités qui découle de cette philosophie est la possibilité de créer ses propres fils d’actualité. Les autres utilisateurs peuvent ensuite suivre vos fils et les afficher sur leur page d’accueil.
Cela ouvre la possibilité à chacun de proposer ses propres algorithmes pour sélectionner du contenu, par rapport à des thématiques spécifiques ou en utilisant des critères tels que le nombre de reposts ou de likes.
Cependant créer son propre fil reste une tâche assez technique. Et cet article a pour vocation d’être un guide pas à pas expliquant d’une manière la plus simple possible, comment faire en utilisant le langage Go. Pas besoin d’être un expert en Go pour lire ce qui va suivre, mais avoir quelques notions peut aider à parcourir l’article plus facilement. Il faut savoir que la documentation officielle donne des exemples en Typescript, et qu’il en existe, faits par la communauté en Python et en Ruby.
Tous le code est issu de ce repo : https://gitlab.com/Dhawos/bluesky-custom-feeds. N’hésitez pas à aller y jeter un œil pour comprendre plus en détail dans quel contexte est utilisé chaque snippet de code présenté ici.
Les différentes étapes
Pour mettre en place son propre fil d’actualité, il va falloir réaliser plusieurs étapes :
1.Enregistrer le fil d’actus sur son compte Bluesky : Il va s’agir d’un script à lancer pour enregistrer son fil d’actus sur son profil Bluesky. Pour cela il sera nécessaire d’avoir un compte et un nom de domaine dont on a le contrôle. C’est sous ce nom de domaine que nous hébergerons notre serveur plus tard.
2.Indexer le contenu qui est créé sur Bluesky : Avant de pouvoir choisir quels posts montrer aux utilisateurs de notre fil, il va nous falloir enregistrer les posts et autre événements qui se produisent sur le réseau afin de les indexer et de pouvoir s’en servir pour décider lesquels afficher ou non.
3.Développer le serveur : La dernière étape qui consiste à implémenter un serveur web qui va répondre à des requêtes bien spécifiques (décrites dans le protocole). Chaque demande d’un utilisateur pour voir notre fil va déclencher une requête partant de l’application Bluesky vers notre serveur web. Charge ensuite à notre serveur de prendre la décision de quels posts l’utilisateur devrait voir et de les transmettre à Bluesky qui se chargera d’afficher ceux-ci à l’utilisateur.
Voyons maintenant tout ceci dans le détail.
1. Enregistrer son fil d’actus
Il s’agit de l’étape la plus simple. Pour que notre fil d’actualité soit utilisable, il faut d’abord que Bluesky soit au courant de son existence, pour ça nous allons utiliser un petit script qui va nous permettre de l’enregistrer. Nous allons utiliser la bibliothèque indigo qui est le SDK Bluesky en Go.
package main
import (
...
"github.com/bluesky-social/indigo/api/atproto"
"github.com/bluesky-social/indigo/api/bsky"
"github.com/bluesky-social/indigo/lex/util"
"github.com/bluesky-social/indigo/xrpc"
)
Voici ce que ça va donner (je coupe volontairement quelques parties pour ne pas faire trop long). Il va nous falloir récupérer un certain nombre d’informations qui vont caractériser notre fil :
recordName := feed.ShortName()
displayName := feed.DisplayName()
description := feed.Description()
avatarBytes := feed.Avatar() //[]bytes d'un fichier d'image
Ensuite, on va préparer notre client pour faire notre requête à l’API Bluesky. Pour ça on va avoir besoin de notre handle (notre pseudo avec le domaine). Dans mon cas il s’agit de : @dhawos.dev. Il faudra également un “application password” que l’on peut générer ici.
client := xrpc.Client{
Host: "https://bsky.social",
}
ctx := context.Background()
if _, err := atproto.ServerDescribeServer(ctx, &client); err != nil {
panic(err)
}
authInput := atproto.ServerCreateSession_Input{
Identifier: handle, // notre handle
Password: appPassword, // notre application password
}
authOutput, err := atproto.ServerCreateSession(ctx, &client, &authInput)
if err != nil {
panic(err)
}
client.Auth = &xrpc.AuthInfo{
AccessJwt: authOutput.AccessJwt,
RefreshJwt: authOutput.RefreshJwt,
Handle: authOutput.Handle,
Did: authOutput.Did,
}
// ici on va renseigner notre distribituted identifier (DID)
// pour notre fil d'actus. Ici hostname doit correspondre au domaine
// que vous contrôlez et ou vous souhaiter héberger votre serveur
feedDID := fmt.Sprintf("did:web:%s", hostname)
var avatar *util.LexBlob
if avatarBytes != nil {
uploadOutput, err := atproto.RepoUploadBlob(ctx, &client, bytes.NewReader(avatarBytes))
if err != nil {
panic(err)
}
avatar = uploadOutput.Blob
}
putInput := atproto.RepoPutRecord_Input{
Collection: "app.bsky.feed.generator",
Record: &util.LexiconTypeDecoder{Val: &bsky.FeedGenerator{
Avatar: avatar,
CreatedAt: time.Now().Format(time.RFC3339),
Description: &description,
Did: feedDID,
DisplayName: displayName,
}},
Repo: client.Auth.Did,
Rkey: recordName,
}
putOutput, err := atproto.RepoPutRecord(ctx, &client, &putInput)
if err != nil {
panic(err)
}
fmt.Printf("Feed %s published\n", recordName)
fmt.Println(putOutput)
}
Notez bien l’output qui va être affiché si tout s’est bien passé, nous en aurons besoin plus tard.
Si tout a fonctionné vous devriez pouvoir voir sous votre profil Bluesky, votre tout nouveau fil d’actus :
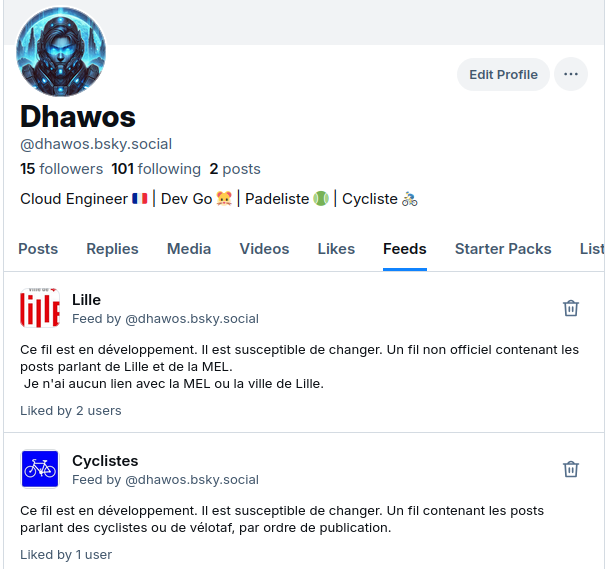
2. Indexer le contenu de Bluesky
Maintenant que notre fil est créé du point de vue de Bluesky il va falloir le mettre en place de notre côté. Mais avant de pouvoir suggérer des posts à nos utilisateurs, il faut déjà que nous sachions quels posts existent sur le réseau.
Pour ce faire nous allons utiliser Jetstream. C’est un service open-source mis à disposition par Bluesky qui permet de facilement récupérer tout le contenu produit sur le réseau. Une petite précision tout de même, ce service ne fait pas strictement partie des spécifications de Bluesky et donc il pourrait être amené à changer dans le futur. Néanmoins il est plus simple à utiliser que le flux officiel (Firehose).
Pour indexer le contenu il va également nous falloir une base de données. Dans notre cas, ce sera PostgreSQL. Nous ferons notamment usage de sa fonctionnalité de recherche de texte.
Commençons par développer un processus qui va tourner en continu et surveiller ce qui se passe sur le réseau. Pour ce faire nous allons définir un type qui aura pour responsabilité d’écouter les événements et de sauvegarder les informations pertinentes en base de données.
package firehose
import (
...
)
type FirehoseListener struct {
db *repository.Queries
logger *slog.Logger
}
func NewFirehoseListener(db *repository.Queries) FirehoseListener {
return FirehoseListener{db: db, logger: slog.Default()}
}
Puis nous allons instancier ce listener dans notre main :
package main
import (
"context"
"fmt"
"log/slog"
"os"
"bluesky-custom-feeds/internal/firehose"
"bluesky-custom-feeds/internal/repository"
"github.com/jackc/pgx/v5/pgxpool"
)
func main() {
ctx := context.Background()
dbHostname, dbHostnameSet := os.LookupEnv("FEED_DB_HOST")
if !dbHostnameSet {
slog.Error("FEED_DB_HOST env var not set")
os.Exit(1)
}
dbPassword, dbPasswordSet := os.LookupEnv("FEED_DB_PASSWORD")
if !dbPasswordSet {
slog.Error("FEED_DB_PASSWORD env var not set")
os.Exit(1)
}
connectionString := fmt.Sprintf("user=blueskyfeeds dbname=bluesky sslmode=disable host=%s password=%s", dbHostname, dbPassword)
pool, err := pgxpool.New(ctx, connectionString)
if err != nil {
panic(err)
}
defer pool.Close()
queries := repository.New(pool)
subscriber := firehose.NewFirehoseListener(queries)
}
Nous avons la structure de base de notre programme, il nous faut maintenant écrire la fonction qui va démarrer l’écoute. Avant cela nous avons besoin de comprendre la base du protocole AtProto qui est la fondation de Bluesky. Dans ce protocole chaque utilisateur possède un repository, à l’instar d’un repository Git. Tout ce que va produire cet utilisateur va donner lieu à un nouveau commit dans une “collection” donnée. C’est ce que nous avons fait lorsque nous avons enregistré notre fil. Nous avons tout simplement créé un nouveau commit dans notre collection app.bsky.feed.generator avec les informations que nous avons données.
Pour le moment, nous allons uniquement surveiller les événements correspondant à la création de commit, il est également possible de recevoir des événements de mise à jour ou de suppression de commit mais ils ne nous seront pas utiles pour ce que nous cherchons à faire.
// Une collection c'est un type d'événement qui peut se produire
// Nous allons écouter uniquement, les posts, reposts et les likes
const (
postCollection = "app.bsky.feed.post"
likeCollection = "app.bsky.feed.like"
repostCollection = "app.bsky.feed.repost"
)
func (fh *FirehoseListener) SubscribeJetstream() {
uri := "wss://jetstream2.us-east.bsky.network/subscribe"
ctx := context.Background()
// Ici nous allons déclarer la fonction a exécuter pour chaque événement
// arrivant sur le JetStream
scheduler := jssequential.NewScheduler("stream", fh.logger, func(ctx context.Context, e *models.Event) error {
// Nous n'écoutons que les créations de commit
if e.Commit == nil || e.Commit.Operation != models.CommitOperationCreate {
return nil
}
// Uniquement les nouveaux posts nous intéressent pour le moment
// Si vous voulez compter les likes ou les reposts il faudra
// traiter les événements sur ces collections également
switch e.Commit.Collection {
case postCollection:
var post bsky.FeedPost
// Récupération du post au format JSON
err := json.Unmarshal(e.Commit.Record, &post)
if err != nil {
fh.logger.Error("unmarshalling post", "err", err)
}
// Traitement et sauvegarde du poste
err = fh.onPostCreate(ctx, &post, e.Commit.CID, e.Did, e.Commit.RKey)
if err != nil {
fh.logger.Error("handling post", "err", err)
}
}
return nil
})
// Initialisation du client Jetstream, ici nous nous intéressons
// uniquement au posts, likes et reposts
config := client.ClientConfig{
Compress: true,
WebsocketURL: uri,
WantedDids: []string{},
WantedCollections: []string{
postCollection,
likeCollection,
repostCollection,
},
MaxSize: 0,
ExtraHeaders: map[string]string{},
}
jsClient, err := client.NewClient(&config, fh.logger, scheduler)
if err != nil {
panic(err)
}
// On reprend la lecture à partir de l'instant présent
// Il serait aussi possible de sauvegarder là ou nous en sommes dans le flux
// afin de ne pas avoir de "trous" si jamais notre service venait à planter.
cursor := time.Now().Unix()
jsClient.ConnectAndRead(ctx, &cursor)
}
Il nous manque encore la fonction principale qui va sauvegarder le post en base de données :
func (fh *FirehoseListener) onPostCreate(ctx context.Context, post *bsky.FeedPost, cid string, repoDID string, path string) error {
if post.Reply != nil {
return nil
}
// Nous ne sauvegardons que les post en français et en anglais.
// Ici vous pouvez ajouter la logique de filtrage qui vous plait
if !slices.Contains(post.Langs, "fr") && !slices.Contains(post.Langs, "en") {
return nil
}
for _, lang := range post.Langs {
fh.db.TagPostLang(ctx, repository.TagPostLangParams{
PostID: cid,
Lang: lang,
})
}
// Je sauvegarde le post en base de donnée
// le plus important à sauvegarder et le "atUri" correspondant au post
// car c'est ce que nous devrons retourner à Bluesky lorsqu'il nous transmettra les requêtes
params := repository.CreatePostParams{
// le cid pour "content ID" n'est pas strictement nécessaire à sauvegarder
Cid: cid,
// repoDID = identifiant du repository de l'utilisateur
// postCollection = "app.bsky.feed.post"
// path = la "record key" qui correspond à un identifiant du post
AtUri: fmt.Sprintf("at://%s/%s/%s", repoDID, postCollection, path),
// On sauvegarde le texte pour pouvoir faire des recherches dedans
Text: post.Text,
IndexedAt: pgtype.Timestamptz{
Time: time.Now(),
InfinityModifier: 0,
Valid: true,
},
}
_, err := fh.db.CreatePost(ctx, params)
if err != nil {
fh.logger.Error(err.Error())
return fmt.Errorf("indexing post : %w", err)
}
return nil
}
Il ne nous reste plus qu’à appeler cette fonction à la fin de notre fichier main.go :
subscriber.SubscribeJetstream()
Et voilà, avec ceci et si le PostgreSQL tourne en arrière plan, il est possible de lancer le programme avec la commande :
go run cmd/indexer/main.go
Si tout va bien, vous devriez commencer à voir arriver des posts dans votre base de données. Attention cependant car elle risque de vite se remplir. Je ne l’ai pas inclus dans mes exemples mais j’ai également écrit une fonction qui permet de nettoyer régulièrement tous les posts plus vieux qu’un seuil donné, ceci afin d’éviter que la base de donnée ne soit remplie au fil du temps. Nous y reviendrons.
3. Développer son serveur
Avec notre base de données qui commence à se remplir, nous allons pouvoir mettre en place la dernière pièce du puzzle. Pour cela nous allons mettre un serveur web assez basique en place qui aura deux fonctionnalités :
- Valider notre identité vis à vis de Bluesky
- Répondre aux requêtes de fil d’actus
Dans un premier temps mettons en place les premières briques pour notre serveur, tout d’abord la mise en place d’un controller qui va répondre aux requêtes de différents fil d’actus :
package handlers
type FeedController struct {
hostname string
feedDID string
serviceDID string
feeds map[string]feeds.BlueskyFeed
}
func NewFeedController(db *repository.Queries, hostname string, feedDID string, serviceDID string) FeedController {
// Ici j'utilise mon propre type pour définir un fil d'actus, vous pouvez remplacer
// par les vôtres
newFeeds := []feeds.BlueskyFeed{
feeds.NewCyclingFeed(db),
feeds.NewLilleFeed(db),
}
feeds := make(map[string]feeds.BlueskyFeed, len(newFeeds))
for _, feed := range newFeeds {
feeds[feed.ShortName()] = feed
}
return FeedController{hostname: hostname, feedDID: feedDID, serviceDID: serviceDID, feeds: feeds}
}
Et ensuite dans le fichier main.go de notre serveur :
package main
func main() {
...
connectionString := fmt.Sprintf("user=blueskyfeeds dbname=bluesky sslmode=disable host=%s password=%s", dbHostname, dbPassword)
ctx := context.Background()
pool, err := pgxpool.New(ctx, connectionString)
if err != nil {
panic(err)
}
defer pool.Close()
queries := repository.New(pool)
// queries est le pool de connexion à notre BDD
// hostname notre nom de domaine sur lequel nous allons répondre
// feedDID correspond à la valeur retournée lors de la création du fil via notre script
// serviceDID correspond au DID de votre serveur, au format "did:web:<hostname>"
// dans mon cas : "did:web:blueskyfeeds.dhawos.dev"
feedController := handlers.NewFeedController(queries, hostname, feedDID, serviceDID)
r := gin.Default()
r.GET("/healthz", func(c *gin.Context) {
c.JSON(200, gin.H{
"status": "ok",
})
})
xrpc := r.Group("/xrpc")
{
// C'est sur cette URL que le service Bluesky va nous contacter
// lorsqu'un utilisateur va faire une requête de fil d'actus
xrpc.GET("/app.bsky.feed.getFeedSkeleton", feedController.FeedGenerator)
// Cette fonction describeFeedGenerator n'est pas techniquement requise
xrpc.GET("/app.bsky.feed.describeFeedGenerator", feedController.DescribeFeedGenerator)
}
// Cette URL est celle que Bluesky va utiliser pour vérifier notre identité
r.GET("/.well-known/did.json", feedController.WellKnownDID)
r.Run() // listen and serve on 0.0.0.0:8080
}
Validation d’identité
Avant de nous envoyer une requête pour un fil d’actus, Bluesky va d’abord vouloir valider notre identité. Il existe plusieurs méthodes pour cela did:web et did:plc. Nous allons nous focaliser sur la méthode did:web car c’est la plus simple à mettre en place. Elle a cependant la limitation de ne pas supporter la migration de domaines, donc assurez-vous que le domaine que vous avez choisi pour votre fil d’actus vous convient car il sera pénible d’en changer.
Tout ce que nous avons à faire pour cela est de retourner un document JSON au bon format, dans mon cas :
{
"@context": [
"https://www.w3.org/ns/did/v1"
],
"id": "did:web:blueskyfeeds.dhawos.dev",
"service": [
{
"id": "#bsky_fg",
"type": "BskyFeedGenerator",
"serviceEndpoint": "https://blueskyfeeds.dhawos.dev"
}
]
}
Voici le code qui permet de faire cette réponse :
func (fc *FeedController) WellKnownDID(c *gin.Context) {
if !strings.HasSuffix(fc.serviceDID, fc.hostname) {
c.JSON(http.StatusNotFound, gin.H{})
return
}
result := wellKnownDIDResponse{
Context: []string{"https://www.w3.org/ns/did/v1"},
ID: fc.serviceDID,
Service: []wellKnownDIDResponseService{
{
Id: "#bsky_fg",
Type: "BskyFeedGenerator",
ServiceEndpoint: fmt.Sprintf("https://%s", fc.hostname),
},
},
}
c.JSON(http.StatusOK, result)
}
Réponse à une requête de fil d’actus
Nous arrivons à la dernière brique à mettre en place pour que tout le système fonctionne. Regardons d’abord ce qu’il se passe lorsqu’un utilisateur navigue sur un fil d’actualité.
- L’utilisateur charge son fil d’actualité
- Bluesky va récupérer les informations lié à ce fil d’actualité
- Bluesky va vérifier l’identité lié au fil d’actualité (ce que nous venons d’implémenter)
- Bluesky va effectuer une requête sur le nom de domaine enregistré avec le fil d’actus. Cette requête va être faite sur le endpoint suivant :
https://<hostname/xrpc/app.bsky.feed.getFeedSkeleton?feed=at://<feedDID>/app.bsky.feed.generator/<feedName>&limit=<limit>&cursor=<cursor>.
Voici un exemple de réponse valide pour cette requête :
{
"cursor": "17533861",
"feed": [
{
"post": "at://did:plc:h6uiyakv4szt7lwe7qioiuzq/app.bsky.feed.post/3lhdtxq7gwc2y"
},
{
"post": "at://did:plc:r5ucobelmauof6krhzn4ltja/app.bsky.feed.post/3lhdtfjh6rs27"
},
{
"post": "at://did:plc:6vul7s776b53z3xsttsveiae/app.bsky.feed.post/3lhdrwehye223"
},
{
"post": "at://did:plc:grxrtsbervppan4gxjvsvilc/app.bsky.feed.post/3lhdrksjhds2i"
},
...
]
}
Le champ cursor dans la requête et dans la réponse sera utilisé pour la pagination. C’est un champ opaque qui est juste récupéré par Bluesky et renvoyé à la prochaine requête. L’utilisation de cette valeur est à la discrétion complète du développeur du fil d’actus. Dans notre cas nous utiliserons le cursor pour sauvegarder l’ID en base de donnée du dernier post de notre réponse, afin de pouvoir repartir de celui-ci lorsqu’une page suivante nous sera demandée. Comme ces IDs sont générés de manière séquentielle, nous aurons la garantie de retourner les posts du plus récent au plus vieux.
Voyons comment générer une telle réponse dans notre code.
func (fc *FeedController) FeedGenerator(c *gin.Context) {
// Nous récupérons les informations de la requête et nous validons que les format
// et les valeurs attendues sont les bonnes
feed := c.Query("feed")
if feed == "" {
c.JSON(http.StatusBadRequest, gin.H{})
return
}
atURI, err := syntax.ParseATURI(feed)
if err != nil {
slog.Error("invalid feed", "feed", feed, "err", err)
c.JSON(http.StatusBadRequest, gin.H{})
return
}
if atURI.Authority().String() != fc.feedDID {
slog.Error("invalid atURI authority", "authority", atURI.Authority().String(), "expectedAuthority", fc.feedDID)
c.JSON(http.StatusBadRequest, gin.H{})
return
}
expectedCollection := "app.bsky.feed.generator"
if atURI.Collection().String() != expectedCollection {
slog.Error("invalid atURI authority", "collection", atURI.Collection().String(), "expectedCollection", expectedCollection)
c.JSON(http.StatusBadRequest, gin.H{})
return
}
// Comme nous avons plusieurs fil d'actus nous devons choisir lequel utiliser en
// fonction des paramètres de la requête
algo, exists := fc.feeds[atURI.RecordKey().String()]
if !exists {
slog.Error("non existant feed", "feed", atURI.RecordKey())
c.JSON(http.StatusBadRequest, gin.H{})
return
}
// Si jamais le cursor n'est pas défini, nous mettons une valeur négative
// Ainsi nous démarrerons notre requête en base de donnée depuis le début
cursor := c.Query("cursor")
if cursor == "" {
cursor = "-1"
}
cursorInt64, err := strconv.ParseInt(cursor, 10, 64)
if cursorInt64 < 0 {
cursorInt64 = math.MaxInt64
}
if err != nil {
slog.Error("could not parse cursor", "cursor", cursor, "err", err)
c.JSON(http.StatusBadRequest, "")
return
}
// Nous devons également honorer le nombre de posts voulu par Bluesky
limit := c.Query("limit")
if limit == "" {
limit = DEFAULT_FEED_LIMIT
}
limitInt, err := strconv.ParseInt(limit, 10, 32)
limitInt32 := int32(limitInt)
if err != nil {
slog.Error("could not parse limit", "limit", limit, "err", err)
c.JSON(http.StatusBadRequest, "")
return
}
req := feeds.FeedRequest{
Lang: "fr",
Cursor: cursorInt64,
Limit: limitInt32,
}
// Nous appelons ensuite notre fonction qui va nous remonter les posts
// pertinents pour un fil d'actus donné
response, err := fc.feeds[algo.ShortName()].GetFeedSkeleton(c, req)
if err != nil {
slog.Error("could not generate feed", "feed", feed, "err", err)
c.JSON(http.StatusInternalServerError, "")
return
}
c.JSON(http.StatusOK, response)
}
Voici l’implémentation du fil d’actus sur le vélo et les cyclistes :
type FeedResponse struct {
Post string `json:"post"`
}
type FeedSkeletonResponse struct {
Cursor string `json:"cursor"`
Feed []FeedResponse `json:"feed"`
}
func (cf *CyclingFeed) GetFeedSkeleton(ctx context.Context, req FeedRequest) (FeedSkeletonResponse, error) {
// Cette implémentation se basera sur une simple recherche de mot clé
const query = "vélo | cycliste | vélotaf"
params := repository.FullTextSearchParams{
ID: req.Cursor,
Lang: req.Lang,
Limit: req.Limit,
ToTsquery: query,
}
queryResult, err := cf.db.FullTextSearch(ctx, params)
if err != nil {
return FeedSkeletonResponse{}, fmt.Errorf("searching for %q : %w", query, err)
}
results := make([]FeedResponse, len(queryResult))
lastCursor := int64(0)
for i, queryResult := range queryResult {
results[i] = FeedResponse{Post: queryResult.AtUri.String}
lastCursor = queryResult.ID.Int64
}
response := FeedSkeletonResponse{
Cursor: strconv.FormatInt(lastCursor, 10),
Feed: results,
}
return response, nil
}
J’utilise sqlc pour générer mon code qui va exécuter les requêtes en base de données. Voici la requête utilisée dans ce cas (je met de côté le code Go généré car il ne nous apporte pas grand chose pour l’explication).
-- name: FullTextSearch :many
SELECT id,at_uri FROM bluesky_posts
RIGHT JOIN post_languages ON cid = post_id
WHERE id < $1
AND lang = $2
AND text_search @@ to_tsquery($4)
ORDER BY id DESC
LIMIT $3;
Cette requête va donc chercher tous les posts qui sont dans une langue donnée, pour lesquels l’identifiant est inférieur au cursor. Nous utilisons la fonctionnalité to_tsquery de PostgreSQL afin de faire une recherche de texte et de remonter les posts qui sont pertinents pour cette requête. Et finalement nous limitons le nombre de résultats avec la limite qui nous a été donnée par Bluesky.
Pour que la pagination fonctionne bien, il est très important que le résultat de cette requête ne fluctue pas au cours du temps. C’est pour ça que nous utilisons ici l’identifiant du post (qui correspond à son ordre d’arrivée dans la base de donnée).
Et voilà le tour est joué, il suffit maintenant de lancer ce code en local et de faire pointer le nom de domaine utilisé plus haut sur sa machine, ou alors packager ce code et l’héberger à l’endroit souhaité. Une fois que c’est fait, vous pouvez aller sur votre profil Bluesky pour y retrouver votre fil d’actualité et tester que tout marche bien.
Mettre en place un nettoyage régulier
Si tout marche bien, félicitations. Il va cependant falloir faire une dernière étape si vous ne voulez pas que votre base de données grossisse à l’infini. Comme il y a quand même beaucoup de trafic sur Bluesky, la base peut se remplir très vite et donc ce nettoyage régulier est important.
Pour cela, nous allons tout simplement lancer une goroutine en parallèle de mon processus d’indexation des posts. Cette goroutine va lancer une commande à intervalle régulier pour supprimer les posts vieux de plus de 48h.
func (fh *FirehoseListener) deleteOldPosts(ctx context.Context) error {
const olderThan = time.Hour * time.Duration(-48)
cuttingPoint := time.Now().Add(olderThan)
fh.logger.Info("deleting posts before", "cuttingPoint", cuttingPoint.String())
err := fh.db.DeletePostsBefore(ctx, pgtype.Timestamptz{
Time: cuttingPoint,
InfinityModifier: 0,
Valid: true,
})
if err != nil {
return fmt.Errorf("deleting old posts : %w", err)
}
// Le vacuum est important pour ne pas que PostgreSQL continue
// à utiliser de l'espace disque alors que beaucoup de lignes
// ont été supprimées
err = fh.db.Vacuum(ctx)
if err != nil {
return fmt.Errorf("doing vacuum: %w", err)
}
return nil
}
func (fh *FirehoseListener) RunGarbageCollectorInBackground(ctx context.Context) {
ticker := time.NewTicker(time.Hour * 2)
quit := make(chan struct{})
go func() {
for {
select {
case <-ticker.C:
err := fh.deleteOldPosts(ctx)
if err != nil {
fh.logger.Error("failed", "err", err.Error())
}
case <-quit:
ticker.Stop()
return
}
}
}()
}
Conclusion
Merci d’avoir lu jusqu’ici. J’espère que ces quelques explications vous auront permis de voir plus clairement quelles sont les différentes étapes nécessaires à la mise en place de son propre fil d’actualités Bluesky. Mon code source complet est à disposition ici : https://gitlab.com/Dhawos/bluesky-custom-feeds alors n’hésitez pas à aller y jeter un coup d’œil.
Dites moi si vous avez aimé cet article sur mon Bluesky : @dhawos.dev. Et si il vous a aidé à mettre le votre en place alors partagez-le, je suis curieux de voir ce que vous allez créer.
Si les sujets de mes propres fils vous intéressent ils sont disponibles ici :
- Un fil sur les posts qui parle de cyclisme et de vélotaf : https://bsky.app/profile/dhawos.dev/feed/velo
- Un fil sur les actualités de Lille et sa métropole : https://bsky.app/profile/dhawos.dev/feed/lille