Pour la première fois j’ai pu finir l’Advent of Code en entier (et dans les temps). C’est un défi annuel, un calendrier de l’Avent qui propose chaque jour un nouveau problème de programmation à résoudre. Il est possible de les résoudre dans n’importe quel langage , en effet, il suffit de donner la réponse au problème, peu importe la méthode employée. Certains vont même jusqu’à le faire dans des feuilles Excel où directement dans vim.
J’aime utiliser l’Advent of Code (AoC) comme une opportunité pour m’entrainer et apprendre de nouvelles choses. Aujourd’hui je voudrais partager ce que j’ai pu apprendre avec l’édition de cette année.
Petite note : Je vais parler de Go dans ce post car c’est le langage que j’ai utilisé, cependant une compréhension avancée du langage Go n’est pas requise pour lire ce blog. Les seules choses à savoir sont qu’en Go le type slice correspond à un tableau dynamique et le type map correspond aux tableaux associatifs (dictionnaries en Python, par exemple)
1. Les “Generics” en Go
J’étais déjà familier avec le concept de generics (ou templates en C++). L’idée est de définir des types ou des fonctions qui au lieu de fonctionner pour un type de variable spécifié en amont, va fonctionner pour un ensemble de types. Il est souvent possible de rajouter des contraintes sur quels types concrets vont être autorisés.
Par exemple, voici comment définir une pile qui fonctionnerait avec différents types de variables.
type Heap[] []int // Implémentation spécifique, ne fonctionne qu'avec des entiers
type Heap[T Comparable] []T // Implémentation générique, fonctionne avec tous les types "Comparable"
Je n’ai pas souvent l’occasion d’utiliser les generics dans mon travail. Mais pour l’AoC c’est vraiment très adapté. Je m’en suis servi pour définir un type personnalisé qui représente une grille en deux dimensions, c’est un schéma qui revient très souvent dans les différents problèmes. Tous les memes sur le subreddit r/adventofcode qui parlent de grille en 2D en témoignent.
type Grid[T any] struct {
Nodes map[Point]T
Height, Width int
}
J’ai ensuite défini des fonctions très utiles sur ce type, comme par exemple le fait de récupéré tous les voisins d’un point donné.
func (grid *Grid[T]) CarthesianNeighbors(point Point) iter.Seq[T] {
return func(yield func(T) bool) {
for _, dir := range CarthesianDirections {
neighbor := point.Add(dir)
if node, ok := grid.Nodes[neighbor]; ok {
if !yield(node) {
break
}
}
}
}
}
C’est très utile car les grilles que l’on rencontre peuvent représenter des choses différentes. Mais peu importe ce qui est représenté, ces fonctions marcheront toujours.
Même si c’est rarement un problème pour l’AoC, il faut noter qu’utiliser cet outil ne va pas engendrer de dégradation de performance au runtime. En effet, à la compilation, le compilateur va déterminer tous les types sur lesquels cette fonction est appelée. Pour chacun d’entre eux, il va générer une copie de cette fonction.
2. Les iterators en Go
Go n’est vraiment pas le langage le plus adapté pour faire l’AoC. C’est un super choix pour développer des serveurs ou pour travailler avec tout l’outillage DevOps, mais les problèmes de l’AoC nécessitent souvent de travailler sur des conteneurs tels que des slices ou des maps. Ces fonctionnalités sont très limités dans la bibliothèque standard de Go.
Ce n’est pas rare que les problèmes se présentent sous la forme d’une liste. Sur chaque élément de cette liste, il faut appliquer un traitement pour en déduire une valeur. Et pour finir il faut souvent combiner ces résultats d’une manière ou d’une autre en en faisant la somme, ou le produit. Ce genre de fonctionnalité est disponible dans d’autres langages (comme JavaScript) sous la forme de fonction map, filter et reduce. Cependant, celles-ci n’existent pas en Go.
Évidemment il est toujours possible de faire ce genre de traitement sous forme d’une boucle for. Mais l’arrivée relativement récente des iterators dans le langage était la bonne occasion de tester ce que pouvait donner ce genre de fonctions en Go. Le combo parfait pour travailler les generics, les iterators et accélérer la résolution des problèmes.
Cela peut vraiment faire la différence sur certains jours. J’en veux pour exemple ma partie 1 pour le jour 22.
func part1(input []string) int {
deriveSecret := func(secret int) int {
for range 2000 {
secret = nextSecret(secret)
}
return secret
}
initialSecrets := functions.Map(slices.Values(input), functions.MustAtoi)
results := functions.Map(initialSecrets, deriveSecret)
return functions.Sum(results)
}
Ce code va simplement transformer chaque ligne en int depuis la liste de string que constitue l’entrée du problème. Puis il va appliquer la fonction deriveSecret pour chacune de ces entrées et finalement en faire la somme.
J’ai eu un peu de mal à appréhender les iterators de Go en lisant la documentation officielle, alors je vais tenter de résumer succinctement leur fonctionnement.
En fait un iterator en Go n’est rien d’autre qu’une fonction avec une signature particulière. Cette fonction prend une autre fonction comme argument (conventionnellement appelée yield). Pour écrire un iterator il suffit d’appeler la fonction yield sur chacun des éléments sauf si cette fonction yield renvoie false ce qui signifie que l’iteration doit s’arrêter.
Voici par exemple mon implémentation de la fonction Map qui applique une opération à chaque élément d’une collection :
// Map iterates a sequence by applying a function to each
// element in the input sequence
func Map[T any, U any](input iter.Seq[T], operation func(T) U) iter.Seq[U] {
return func(yield func(U) bool) {
for element := range input {
if !yield(operation(element)) {
break
}
}
}
}
Un autre exemple que j’ai pu écrire, l’iterator Pairs dont le but et de prendre deux collections en entrée et me retourner les paires formées en prenant à chaque fois l’élément suivant dans les deux collections :
// Pair will make pair from two iterators and stop once
// the shortest is exhausted
func Pairs[T any](s1, s2 iter.Seq[T]) iter.Seq[Pair[T]] {
return func(yield func(Pair[T]) bool) {
next1, stop1 := iter.Pull(s1)
defer stop1()
next2, stop2 := iter.Pull(s2)
defer stop2()
for {
v1, ok1 := next1()
v2, ok2 := next2()
if !ok1 || !ok2 {
break
}
if !yield(Pair[T]{A: v1, B: v2}) {
break
}
}
}
}
Il est possible de faire n’importe quelle opération dans le corps de la fonction iterator. Tant que la fonction yield est appelée sur chaque élément, sauf si elle retourne false. Je suis heureux d’avoir utilisé cette opportunité pour mieux comprendre l’implémentation de ce concept en Go.
2. Utilisation des outils de profiling
Pendant le mois, j’ai décidé de bencher mes solutions, juste par curiosité, pour voir comment je m’en sortais.
Puis pour le jour 12, j’ai rapidement trouvé une solution qui fonctionnait. En allant fouiller sur le subreddit, j’ai remarqué que mes temps étaient particulièrement lents par rapport à ce que les autres personnes avec une configuration similaire pouvait avoir. Voilà ce que j’avais de mon côté :
❯ go test -bench=.
goos: linux
goarch: amd64
pkg: advent-of-go/solutions/2024/12
cpu: AMD Ryzen 5 5600 6-Core Processor
BenchmarkPart1-12 10 122588965 ns/op
BenchmarkPart2-12 9 136754725 ns/op
PASS
ok advent-of-go/solutions/2024/12 2.724s
136ms pour la partie 2, ce qui n’est pas horrible, mais je me suis demandé si je pouvais faire mieux sans changer significativement mon approche. C’est là que j’ai sorti le profiler Go pour voir si il pouvait me donner des pistes à explorer. Et voici le résultat obtenu :
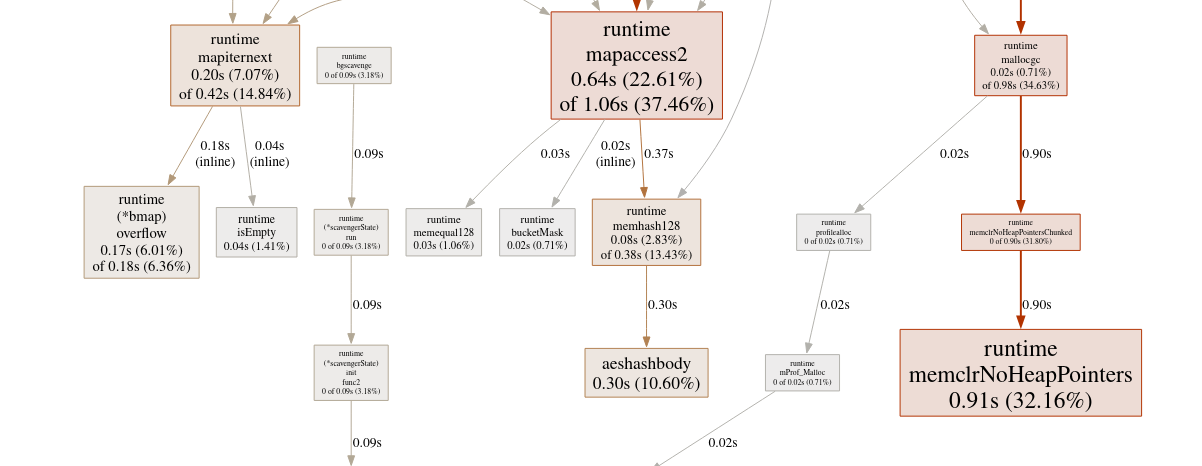
Clairement il a fallu faire un peu de recherches pour comprendre ce que ce graphique voulait dire. Mais en trouvant la signification des fonctions qui apparaissent on se peut se rendre compte que deux choses prennent beaucoup de temps :
- Accéder à des éléments d’une map (le type que j’utilise pour travailler avec des grilles en 2D).
- La garbage collection
En voyant ça, je n’étais pas vraiment sur de ce que je pouvais en faire, mais je me suis demandé si je ne faisais pas trop d’allocations. J’ai donc repris mon code et regardé tous les appels à la fonction make. La fonction make est une fonction qui permet, entre autres, d’allouer de la mémoire pour les slices et les maps. C’était donc un coupable idéal. Et voici ce que j’avais écrit :
crops := make(map[ds.Point]bool, len(grid.Nodes))
Le second paramètre de la fonction make est la quantité de mémoire à réserver. Ici la longueur de grid.Nodes était de 19600, alors qu’en réalité je n’avais besoin de stocker qu’une centaine d’éléments.
En Go, les maps utilisent des “buckets” sous le capot. C’est à dire que pour stocker une paire clé/valeur dans la map, Go va hasher la clé pour trouver dans quel bucket ranger l’élément. Évidemment ces buckets sont créés sur la Heap, donc ils sont coûteux à allouer et ont besoin d’être garbage collectés. Dans ces conditions on comprend bien pourquoi réserver autant de place en avance est en réalité une mauvaise idée
J’ai donc fait ce changement :
crops := make(map[ds.Point]bool, 0)
Et ma solution tourne maintenant presque 10 fois plus vite.
❯ go test -bench=.
goos: linux
goarch: amd64
pkg: advent-of-go/solutions/2024/12
cpu: AMD Ryzen 5 5600 6-Core Processor
BenchmarkPart1-12 96 11678739 ns/op
BenchmarkPart2-12 78 14791988 ns/op
PASS
ok advent-of-go/solutions/2024/12 2.306s
La morale de cette histoire : Tenter de mettre la bonne taille pour initialiser une map c’est une bonne chose. Mais il ne faut pas trop en abuser non plus car ces allocations ne sont pas gratuites. C’est quelque chose auquel je vais faire plus attention dans le futur.
3. Récursion et Memoization
Pour plusieurs jours, comme le jour 19 et le le jour 21, la partie requiert d’explorer un espace de solutions bien plus large que pour la partie 1. En général, utiliser la même approche dans les deux cas est voué à l’échec.
Il existe une technique relativement simple qui peut aider dans ce genre de cas, et elle s’appelle : La memoization La memoization est une technique parfaitement logique une fois qu’on la connait. Mais lorsque j’ai fait mes premiers problèmes AoC, je ne maitrisais pas cette technique, en tout cas pas sous ce nom là. L’idée de cette technique est de stocker le résultat de calculs coûteux pour ne pas avoir à les refaire. Je vais utiliser l’exemple du jour 19 pour illustrer comment s’en servir. Donc si vous avez prévu de faire le jour 19 plus tard, attention cette partie va contenir quelques spoilers.
Pour le jour 19, nous avions en entrée un liste de chaînes de caractères comme gbbr. Nous avions également une liste de schéma que l’on pouvait utiliser pour reproduire ces chaînes de caractères : r, wr, b, g, bwu, rb, gb, br.
En y réfléchissant, on peut se dire que finalement, il est possible de découper ce problème en sous problèmes. C’est un bon signe qu’on va pouvoir utiliser une récursion pour traiter le problème, c’est à dire écrire une fonction qui s’appelle elle-même sur un sous problème. Voici ce que ça peut donner dans notre cas :
- Tenter de trouver tous les schéma qui peuvent être utilisés. Dans notre exemple, on peut donc utiliser soit
gbsoitgpour commencer à reproduire notre chaîne de caractères - Pour chacun de ces schéma, tenter de résoudre le sous problème en ayant enlevé ce schéma. Ici on tenterait donc de résoudre les sous problèmes
bbretbr.
Si on applique ce processus, on peut trouver qu’il y a deux manières de faire bbr (b,br et b,b,r) et deux manières de faire br (b,r, et br). Ce qui fait 4 en tout. Voici le code qui fait cela.
func possibleOptions(patterns []string, design string) int {
sum := 0
for _, pattern := range patterns {
if pattern == design {
sum += 1
continue
}
if strings.Index(design, pattern) == 0 {
var result, count int
var cached bool
subDesign := design[len(pattern):]
result = possibleOptions(patterns, subDesign)
sum += result
}
}
return sum
}
Vous avez peut-être remarqué, mais lors de nos calculs, on se rend compte qu’on a calculé deux fois la manière de fabriquer br. Pourtant, aucune circonstance ne viendra changer ce résultat. On peut donc le sauvegarder pour pouvoir le lire plus tard, au lieu de le recalculer à chaque fois. Pour cela, nous allons utiliser une map, et voici ce que ça peut donner :
var cache map[string]int
func possibleOptions(patterns []string, design string) int {
sum := 0
for _, pattern := range patterns {
if pattern == design {
sum += 1
continue
}
if strings.Index(design, pattern) == 0 {
var result, count int
var cached bool
subDesign := design[len(pattern):]
// Avoid computation if we already know the result
if count, cached = cache[subDesign]; cached {
result = count
} else {
result = possibleOptions(patterns, subDesign)
}
sum += result
}
}
// Save the result
cache[design] = sum
return sum
}
En général, la récursivité est un très bon moyen de traiter les problèmes qui peuvent facilement être divisés entre sous problèmes comme celui-là. En théorie il est toujours possible d’utiliser quand même une approche itérative. Mais de mon côté je trouve que lorsque la structure du problème présente ces caractéristiques, y penser en tant que problème récursif permet vraiment de simplifier mon raisonnement.
Et pour la memoization, c’est un outil à garder en tête car il est facile à mettre en place et est souvent très utile dans ce genre de problèmes.
4. Approche pour résoudre les problèmes
J’ai maintenant fait presque deux AoC en entier (20 jours en 2023, et les 25 en 2024). J’ai donc pu développer certains réflexes, qui ont pu m’aider à la longue
- Lire le problème avec attention : Je ne compte plus le nombre de fois ou j’ai perdu un temps fou car je n’ai pas su lire correctement le problème. Prendre quelques minutes pour bien comprendre peut vraiment être un bon calcul.
- Mettre en place des tests avec les exemples : Les petits exemples fournis permettent de raisonner plus facilement sur le problème et de tester ses hypothèses. La plupart du temps, lorsqu’on arrive à avoir une bonne réponse pour les exemples, on a la bonne solution pour le problème général. Même si ce n’est pas toujours le cas
- Ne pas essayer de faire la partie 2 avant la partie 2 : Quand je faisais mes premiers problèmes, je tentais toujours d’anticiper ce que pourrait être la partie 2. Non seulement cela avait tendance à me faire perdre du temps, mais en général j’étais à côté de la plaque et cela me demandait plus de réécriture que si j’avais tout simplement ignoré le fait qu’il y aurait une partie 2.
- Demander de l’aide : Pour le jour 21 (partie 2) et le jour 24 (partie 2), j’ai vraiment été bloqué. Et même si c’est très satisfaisant de résoudre les problèmes sans aucune aide, ça ne vaut pas toujours le coup de perdre des heures (surtout si on a un temps limité à allouer à ces problèmes, comme c’est mon cas). Le subreddit r/adventofcode est une mine d’or d’information pour avoir une idée des approches employées par les autres participants.
Conclusion
Faire l’Advent of Code était une super excuse pour écrire un peu de Go et apprendre en le faisant, tout en s’amusant. Je n’ai pas nécessairement beaucoup d’opportunités de coder en Go au travail alors que j’adore ce langage. C’était donc assez agréable d’avoir la possibilité de le faire. C’est le truc cool avec l’AoC, on peut l’utiliser pour ce qu’on veut, que ça soit se lancer un défi, apprendre un nouveau langage ou juste se faire plaisir sur les premiers jours.
Si vous avez fait l’AoC cette année, j’espère que vous l’avez apprécié autant que moi. Et si vous ne l’avez pas fait, je ne peux que vous inciter à y jeter un œil.
Merci de m’avoir lu, et n’hésitez pas à me dire ce que vous avez pensé de mon article via mon Bluesky : @dhawos.dev.
À une prochaine fois.